04/07/2021
0
Ansichten


Die Regressionsanalyse ist möglicherweise die am weitesten verbreitete multivariate statistische Technik zur Bestimmung der Beziehung zwischen eine oder eine Gruppe unabhängiger Variablen und einer abhängigen Variablen, damit erstere die Änderung der Variablen vorhersagen kann zweite-
Fast von Natur aus versucht der Mensch, Erklärungen für die Ereignisse zu geben, die auf natürliche Weise geschehen. Alltag, „die Person raucht, weil sie sich gestresst fühlt“, „übermäßiges Essen führt zu mehr Körpergewicht“; Wir wissen jedoch, dass die Erklärungen, die wir zu solchen Ereignissen geben, nicht immer richtig sind. Daniel Kahneman beschreibt in seinem Buch „Thinking Fast, Thinking Slow“ wie, obwohl Menschen dazu neigen, alle kognitiven Elemente zu nutzen, die sie besitzen besitzen, werden sie immer Fehler machen, wenn sie versuchen, ein Ereignis zu erklären, was in einer Realität, in der mehrere Faktoren nebeneinander existieren, völlig normal ist. Hälfte. Wie könnten wir also versuchen, Ereignisse so genau wie möglich zu erklären? In den Sozial- und Gesundheitswissenschaften ist dies durch Datenanalyse möglich; Dies ist definiert als eine Reihe von Verfahren, die durch statistische Techniken unterstützt werden beschreibend und inferenziell, um Informationen aus einer empirischen Datenstichprobe zu extrahieren und weiterzuentwickeln Schlussfolgerungen. Im Rahmen der Datenanalyse ist die Technik, die es uns ermöglicht, zuverlässige Erklärungen für Ereignisse zu geben, eine multivariate Technik namens Regressionsanalyse.
Die Regressionsanalyse verfügt über eine Reihe von Varianten wie die lineare Regressionsanalyse, die multiple Regressionsanalyse, Logistische Regression, Mediationsanalyse, Moderationsanalyse und sogar Strukturgleichungsmodelle könnten in Betracht gezogen werden (SEM). Alle diese Varianten folgen jedoch derselben Operationslogik, einer oder mehreren Eingabevariablen, die als Prädiktoren, unabhängige Variablen oder Variablen bezeichnet werden können. Erklärende oder antezedente Variablen sagen die größtmögliche Varianz einer Ausgabevariablen voraus, die als abhängige Variable oder einfach als abhängige Variable bezeichnet werden kann Kriterium; Wenn mehr als eine unabhängige Variable vorhanden ist, ermittelt die Regressionsanalyse auch, welche davon den größten Einfluss auf die abhängige Variable hat.
Um zu verstehen, wie diese Beziehungen entstehen, müssen wir auf die folgende Gleichung zurückgreifen, die ein einfaches lineares Regressionsmodell darstellt:
y = Bentweder +BYo X Und
Wo,
Bentweder = Ursprung der Steigung
BYo = Neigungsgrad der Linie (Slope)
X = VI-Wert
e = Residuen (Fehler)
Einfach ausgedrückt gibt diese Gleichung den Grad an, in dem das Vorhandensein eines Prädiktors (unabhängige Variable) eine Änderung des Kriteriums (abhängige Variable) hervorruft. Es muss erwähnt werden, dass die Gleichung zwar das Residuum (Fehler) erwähnt, dieses jedoch nicht innerhalb des Modellelements geschätzt wird Wofür diese Technik kritisiert werden kann, sondern dass ihre „Evolution“ von Strukturgleichungsmodellen (SEM) entschädigt.
Sobald die Gleichung geschätzt wurde, kann sie mithilfe der folgenden zweidimensionalen Ebene, der sogenannten Regressionslinie, visualisiert werden.
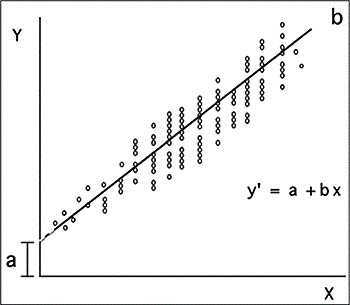
Quelle: Dagnino (2014)
Dieses Diagramm stellt nicht nur die Beziehung der beteiligten Variablen (durch die Punktwolke) dar, sondern zeigt auch eine Linie an gibt diesem Diagramm den Namen und gibt den Grad an, in dem die empirischen Daten zum Regressionswert (dem Wert von B) passen.
Obwohl B uns den Grad der Steigung angibt, ist es für die Interpretation eigentlich nicht sehr nützlich, weil Sie wird in derselben Metrik wie die Variablen ausgedrückt und daher können ihre Werte zu umfangreich sein. Auf diese Weise wird durch Standardisieren von B basierend auf den Z-Scores der Beta-Koeffizient erhalten (β), dessen Werte zwischen 0 und 1 liegen können, sowohl positiv als auch negativ, und das seine erlaubt Deutung. Somit zeigt ein negativer Beta-Wert an, dass die Prädiktorvariable das Kriterium negativ vorhersagt, d. h. je größer das Vorhandensein des Prädiktors, desto unwahrscheinlicher ist das Vorhandensein des Kriteriums; Im Gegenteil bedeutet ein positives Beta, dass das Vorhandensein des Prädiktors das Vorhandensein des Kriteriums begünstigt.
Wie bei anderen inferenzstatistischen Techniken hängt die Interpretation einer Regression davon ab Hypothesenkontrast oder der Signifikanzwert (p), der in den Sozialwissenschaften typischerweise p ist > .05.
Ein elementares Konzept der Regressionsanalyse ist schließlich der R2-Wert, der sich auf die durch das Modell erklärte Varianz bezieht. Regression, die direkt oder durch Multiplikation mit 100 interpretiert werden kann, um den Prozentsatz der Varianz zu erhalten erklärt.
Wie eingangs erwähnt gibt es unterschiedliche Regressionsanalysen. Bisher wurde die einfache und multiple lineare Regression behandelt; diese gehen davon aus, dass sowohl die Prädiktorvariablen als auch das Kriterium stetig sind. Wenn die Variablen jedoch nicht kontinuierlich, also kategorisch, sind, gilt: logistische Regressionsanalyse, dies ist der einzige Unterschied zum Rest Rückschritt.
Hayes, F. ZU. (2018). Einführung in Mediation, Moderation und bedingte Prozessanalyse. Ein regressionsbasierter Ansatz. (2. Auflage). Guilford Press.
