04/07/2021


L'analisi di regressione è forse la tecnica statistica multivariata più utilizzata per determinare la relazione tra una, o un gruppo, di variabili indipendenti e una dipendente in modo che la prima possa prevedere il cambiamento nella secondo-
Quasi innatamente, gli esseri umani cercano di dare spiegazioni agli eventi che accadono naturalmente. nella vita di tutti i giorni, «quella persona fuma perché si sente stressata», «mangiare troppo porta ad un aumento di peso corporeo»; Sappiamo però che le spiegazioni che diamo a tali eventi non sempre sono corrette. Daniel Kahneman nel suo libro “Thinking Fast, Thinking Slow” descrive come, nonostante le persone tendano a utilizzare tutti gli elementi cognitivi di cui dispongono possiedono, commetteranno sempre errori nel tentativo di spiegare qualche evento, il che è del tutto normale in una realtà in cui coesistono molteplici fattori. metà. Allora come potremmo provare a spiegare gli eventi nel modo più accurato possibile? Nelle scienze sociali e sanitarie è possibile farlo attraverso l’analisi dei dati; che è definito come un insieme di procedure aiutate da tecniche statistiche descrittivo e inferenziale al fine di estrarre informazioni da un campione empirico di dati e svilupparle conclusioni. Nell'ambito dell'analisi dei dati, la tecnica che ci permetterà di dare spiegazioni attendibili agli eventi è una tecnica multivariata chiamata Analisi di Regressione.
L'analisi di regressione ha una serie di varianti come l'analisi di regressione lineare, l'analisi di regressione multipla, Si potrebbero prendere in considerazione la regressione logistica, l'analisi di mediazione, l'analisi di moderazione e persino i modelli di equazioni strutturali (SEM). Tuttavia, tutte queste varianti seguono la stessa logica operativa, una o più variabili di input, che possono essere conosciute come predittori, variabili indipendenti, variabili. variabili esplicative o antecedenti, predicono la massima quantità possibile di varianza di una variabile di output, che può essere conosciuta come variabile dipendente o semplicemente criterio; Quando esiste più di una variabile indipendente, l'analisi di regressione determina anche quale di queste ha la maggiore influenza sulla variabile dipendente.
Per comprendere come si verificano queste relazioni, dobbiamo ricorrere alla seguente equazione, che presenta un semplice modello di regressione lineare:
y = BO +BEhi X E
Dove,
BO = Origine della pendenza
BEhi = Grado di inclinazione della linea (pendenza)
X = valore VI
e = Residui (errore)
In parole povere, questa equazione indica il grado in cui la presenza di un predittore (variabile indipendente) produce un cambiamento nel criterio (variabile dipendente). È necessario menzionare che sebbene l'equazione menzioni il residuo (errore), questo non è stimato all'interno del modello, elemento per cui questa tecnica può essere criticata, ma che la sua “evoluzione” dei modelli di equazioni strutturali (SEM) compensa.
Una volta stimata l'equazione, è possibile visualizzarla utilizzando il seguente piano bidimensionale, chiamato retta di regressione.
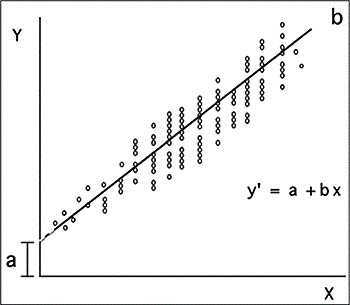
Fonte: Dagnino (2014)
Questo grafico, oltre a presentare la relazione delle variabili in gioco (attraverso la nuvola di punti), espone una linea che dà il nome a questo diagramma e indica il grado in cui i dati empirici si adattano al valore di regressione (il valore di B).
Sebbene B ci indichi il grado di pendenza, in realtà non è molto utile per l'interpretazione perché È espresso nella stessa metrica delle variabili e, pertanto, i suoi valori potrebbero essere troppo estesi. In questo modo, standardizzando B in base agli Z Scores, si ottiene il coefficiente beta (β), i cui valori possono essere compresi tra 0 e 1, sia positivi che negativi e che ne consente interpretazione. Pertanto, un valore beta negativo indicherà che la variabile predittore predice negativamente il criterio, ovvero maggiore è la presenza del predittore, meno probabile è la presenza del criterio; Al contrario, un beta positivo indica che la presenza del predittore favorisce la presenza del criterio.
Come altre tecniche statistiche inferenziali, l'interpretazione di una regressione dipenderà da contrasto di ipotesi, o il valore di significatività (p), che nelle scienze sociali è tipicamente p > .05.
Infine, un concetto elementare dell’analisi di regressione è il valore R2, che si riferisce alla varianza spiegata dal modello. regressione, che può essere interpretata direttamente oppure moltiplicandola per 100 per ottenere la percentuale di varianza spiegato.
Come accennato all’inizio, esistono diverse analisi di regressione. In precedenza, è stata affrontata la regressione lineare semplice e multipla; queste presuppongono che sia le variabili predittive che il criterio siano continui. Quando però le variabili non sono continue, cioè sono categoriali, il analisi di regressione logistica, essendo questa l'unica differenza con il resto del file regressione.
Hayes, F. A. (2018). Introduzione alla mediazione, moderazione e analisi dei processi condizionali. Un approccio basato sulla regressione. (2°. Edizione). Guildford Press.

