
04/07/2021


Z 점수는 변수 간 비교를 목적으로 표준 편차를 기반으로 데이터를 변환한 결과입니다.
Z 점수의 개념과 요소를 심화하려면 Z 점수를 촉진할 몇 가지 관련 이전 개념을 검토해야 합니다. 이해력.
센터. 데이터에서 발견될 가능성이 가장 높은 변수 또는 변수의 값을 나타냅니다. 센터의 가장 일반적인 값은 모든 데이터를 더하고 가지고 있는 데이터의 양으로 나누어 얻은 평균 또는 평균입니다.
분산. 변수의 중심에 대한 값의 거리 또는 집중 정도를 나타냅니다. 가장 일반적인 분산 데이터는 1) 데이터가 평균에서 얼마나 떨어져 있는지 알려주는 표준 편차 또는 표준 편차입니다. 이것은 각 데이터에서 평균값을 빼고 제곱으로 올린 다음 이 값의 평균을 계산하고 마지막으로 이 새로운 평균의 제곱근을 평가하여 계산합니다. 2) 변화, 이것은 표준 편차로 밝혀졌지만 제곱으로 올려지면 표준 편차에 대해 동일한 절차를 따르지만 제곱근을 계산하지 않고 얻습니다.
의 모양 분포. 값 또는 값 범위가 반복되는 빈도를 반영합니다. 다음을 공식화하는 이론적 분포를 구별할 필요가 있습니다. 수학, 경험적 분포는 변수가 샘플에서 취하는 값에 의해 형성됩니다.
의 방법으로 합성, 우리는 중심이 데이터를 대표한다고 말할 수 있습니다. 분산은 중심이 데이터의 좋은 또는 나쁜 표현과 분포의 모양은 데이터가 그룹화된 위치를 감지하는 데 도움이 됩니다. 가치.
에서 수행하는 가장 일반적인 작업 중 하나입니다. 조사 이다 비교 2개 이상의 서로 다른 변수에 대한 데이터를 비교할 수 없다는 문제에 직면하는 경우가 많습니다. 변수는 중심 또는 매우 다른 분포를 나타내거나 더 나쁜 경우 다른 메트릭을 갖습니다. 즉, 다른 방식으로 측정되었습니다(예: 척도 Wechsler는 지능 지수를 측정하기 위해 실행 시간, 정답 또는 답변). 그러한 이유 이 문제를 해결하는 방법이 궁금합니다.
답은 명확합니다. 데이터 변환은 Z 점수 또는 일반 점수 둘 다 동일한 메트릭에 있거나 동일한 스프레드를 갖습니다. 상기 변환은 다음 공식을 사용하여 수행되며, 여기서 x는 값 a입니다. 변환, µ는 원래 분포의 평균이고 σ는 다음의 표준 편차입니다. 원래 배포.
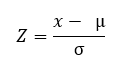
얻은 결과는 표준 편차 단위로 표시되고 데이터 비교에 필요한 요구 사항을 충족하는 점수입니다.
같은 센터로 득점. 원래 분포의 평균에 관계없이 Z 점수로 변환하면 모든 변수의 평균이 0이 됩니다. 이러한 의미에서 양수 Z 점수는 원래 평균보다 높은 점수에 해당하는 반면 음수 점수는 평균보다 낮은 점수에 해당합니다.
스프레드가 동일한 점수. Z 점수의 평균이 0이 되는 것처럼 모든 변수의 산포도 1이 됩니다.
동일한 메트릭의 점수. 새 점수에 대한 메트릭은 표준 편차 단위로 표시됩니다.
Z 점수에는 최소 또는 최대 제한이 없지만 -3에서 3 사이의 값을 갖는 경향이 있습니다. 이 값을 초과하는 값은 다른 유형의 치료가 필요한 비정형 사례를 나타냅니다.
Z 점수는 유일한 것이 아닙니다. 방법 변환에서 대체 옵션은 누적 사례의 백분율을 고려한 점수의 상대적 위치를 나타내는 백분위수입니다. 이 변환은 이전에 설명한 것과 동일한 프로세스를 수행하여 동일한 중심(50), 동일한 분산(0-100) 및 동일한 메트릭(백분율 단위)을 얻습니다.
두 변환의 주요 차이점은 분포 모양의 변경에 있습니다. 백분위수로의 변환에서 이것은 변경되기 때문에 Z 점수에서는 유지됩니다. 동일한. 즉, 데이터 분포가 편향되어 있으면 백분위수로 변환하면 대칭이 되지만 Z 점수로 변환하면 비대칭으로 남게 됩니다.

