0
Keer bekeken


Regressieanalyse is mogelijk de meest gebruikte multivariate statistische techniek om de relatie tussen één, of een groep, van onafhankelijke variabelen en een afhankelijke variabele, zodat de eerste de verandering in de variabele kan voorspellen seconde-
Bijna van nature proberen mensen verklaringen te geven voor de gebeurtenissen die op natuurlijke wijze plaatsvinden. het dagelijks leven, “die persoon rookt omdat hij zich gestrest voelt”, “te veel eten leidt tot een groter lichaamsgewicht”; We weten echter dat de verklaringen die we voor dergelijke gebeurtenissen geven niet altijd correct zijn. Daniel Kahneman beschrijft in zijn boek ‘Thinking Fast, Thinking Slow’ hoe, hoewel mensen de neiging hebben gebruik te maken van alle cognitieve elementen die ze bezitten, zullen ze altijd fouten maken wanneer ze een gebeurtenis proberen te verklaren, wat volkomen normaal is in een realiteit waarin meerdere factoren naast elkaar bestaan. half. Dus hoe kunnen we proberen de gebeurtenissen zo nauwkeurig mogelijk te verklaren? In de sociale en gezondheidswetenschappen is het mogelijk om dit te doen door middel van data-analyse; die wordt gedefinieerd als een reeks procedures die worden ondersteund door statistische technieken beschrijvend en inferentieel om informatie uit een empirische steekproef van gegevens te extraheren en te ontwikkelen conclusies. Binnen de data-analyse is de techniek die ons in staat stelt betrouwbare verklaringen te geven aan gebeurtenissen een multivariate techniek die regressieanalyse wordt genoemd.
Regressieanalyse kent een reeks varianten, zoals lineaire regressieanalyse, meervoudige regressieanalyse, logistieke regressie, mediatieanalyse, moderatieanalyse en zelfs structurele vergelijkingsmodellen kunnen worden overwogen (SEM). Al deze varianten volgen echter dezelfde operationele logica, een of meer invoervariabelen, die bekend kunnen staan als voorspellers, onafhankelijke variabelen, variabelen. verklarende of antecedente variabelen, voorspellen de grootst mogelijke hoeveelheid variantie van een outputvariabele, die bekend staat als de afhankelijke variabele of eenvoudigweg criterium; Wanneer er meer dan één onafhankelijke variabele is, bepaalt de regressieanalyse ook welke van deze de grootste invloed heeft op de afhankelijke variabele.
Om te begrijpen hoe deze relaties ontstaan, moeten we onze toevlucht nemen tot de volgende vergelijking, die een eenvoudig lineair regressiemodel presenteert:
y = Bof +BJo X En
Waar,
Bof = Oorsprong van de helling
BJo = Hellingsgraad van de lijn (helling)
X = VI-waarde
e = Residuen (fout)
Simpel gezegd geeft deze vergelijking aan in welke mate de aanwezigheid van een voorspeller (onafhankelijke variabele) een verandering in het criterium (afhankelijke variabele) teweegbrengt. Het is noodzakelijk om te vermelden dat, hoewel de vergelijking het residu (fout) vermeldt, deze niet binnen het modelelement wordt geschat waarvoor deze techniek kan worden bekritiseerd, maar dat de “evolutie” structurele vergelijkingsmodellen (SEM) compenseert.
Zodra de vergelijking is geschat, kan deze worden gevisualiseerd met behulp van het volgende tweedimensionale vlak, de regressielijn genoemd.
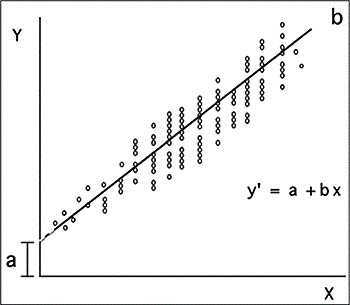
Bron: Dagnino (2014)
Deze grafiek toont niet alleen de relatie tussen de betrokken variabelen (door de puntenwolk), maar legt ook een lijn bloot geeft de naam aan dit diagram en geeft aan in welke mate de empirische gegevens passen bij de regressiewaarde (de waarde van B).
Hoewel B ons de mate van de helling vertelt, is dit eigenlijk niet erg nuttig voor interpretatie, omdat Het wordt uitgedrukt in dezelfde metriek als de variabelen en daarom kunnen de waarden ervan te uitgebreid zijn. Op deze manier wordt, door B te standaardiseren op basis van de Z-scores, de bètacoëfficiënt verkregen (β), waarvan de waarden tussen 0 en 1 kunnen liggen, zowel positief als negatief, en die dit mogelijk maakt interpretatie. Een negatieve bètawaarde zal dus aangeven dat de voorspellende variabele het criterium negatief voorspelt, dat wil zeggen: hoe groter de aanwezigheid van de voorspeller, hoe minder waarschijnlijk de aanwezigheid van het criterium; Integendeel, een positieve bèta geeft aan dat de aanwezigheid van de voorspeller de aanwezigheid van het criterium bevordert.
Net als bij andere inferentiële statistische technieken zal de interpretatie van een regressie afhangen van de hypothesecontrast, of de significantiewaarde (p), die in de sociale wetenschappen doorgaans p is > .05.
Tenslotte is een elementair concept van regressieanalyse de R2-waarde, die verwijst naar de variantie die door het model wordt verklaard. regressie, die direct kan worden geïnterpreteerd of door deze met 100 te vermenigvuldigen om het variantiepercentage te verkrijgen uitgelegd.
Zoals in het begin vermeld, zijn er verschillende regressieanalyses. Eerder werd eenvoudige en meervoudige lineaire regressie behandeld; deze gaan ervan uit dat zowel de voorspellende variabelen als het criterium continu zijn. Wanneer de variabelen echter niet continu zijn, dat wil zeggen dat ze categorisch zijn, wordt de logistische regressieanalyse, aangezien dit het enige verschil is met de rest van de regressie.
Hayes, F. NAAR. (2018). Inleiding tot bemiddeling, moderatie en voorwaardelijke procesanalyse. Een op regressie gebaseerde aanpak. (2e. Editie). Guilford-pers.