0
Visninger


Z-score er resultatet av en transformasjon av dataene basert på standardavviket, med det formål å gjøre sammenligninger mellom variabler.
For å utdype konseptet og elementene i Z-poeng, er det nødvendig å gjennomgå noen relaterte tidligere konsepter som vil lette deres forståelse.
Senter. Det refererer til verdien av variabelen eller variablene som mest sannsynlig finnes i dataene våre. Den vanligste verdien av senteret er gjennomsnittet eller gjennomsnittet, som oppnås ved å legge til alle dataene og dele dem på mengden data de har.
Spredning. Det refererer til graden av avstand eller konsentrasjon av verdiene med hensyn til midten av variablene. De vanligste spredningsdataene er 1) Standardavvik eller standardavvik, som forteller oss hvor langt dataene er fra gjennomsnittet. Dette beregnes ved å trekke gjennomsnittsverdien fra hver data og heve den til kvadratet, deretter beregnes gjennomsnittet av disse verdiene og til slutt beregnes kvadratroten av dette nye gjennomsnittet; 2)
Forskjell, dette viser seg å være standardavviket men hevet til kvadratet, det oppnås etter samme prosedyre for standardavviket, men uten å beregne kvadratroten.Formen på fordeling. Gjenspeiler hvor ofte en verdi eller verdiområde gjentas. Det er nødvendig å skille mellom teoretiske fordelinger, som formulerer matte, mens empiriske fordelinger dannes av verdiene som en variabel tar i et utvalg.
ved hjelp av syntese, vi kan si at senteret er en representant for dataene, spredningen hjelper til med å spesifisere om senteret er en god eller dårlig representasjon av dataene og formen på distribusjonen bidrar til å oppdage hvor dataene er gruppert verdier.
En av de vanligste oppgavene som utføres i etterforskning er den sammenligning av to eller flere forskjellige variabler, men ved mange anledninger står forskerne overfor problemet at dataene deres ikke kan sammenlignes fordi variabler presenterer et senter eller en helt annen fordeling eller enda verre, de har forskjellige metrikker, det vil si at de ble målt på en annen måte (for eksempel skalaene Wechsler, for å måle intelligenskvotienten, har en serie tester som kvalifiserer fra utførelsestidspunktet, de riktige svarene eller fraværet eller tilstedeværelsen av svar). for slikt grunnen til Det gjenstår å lure på hvordan man løser dette problemet?
Svaret er klart, en transformasjon av dataene må utføres i Z-score eller typiske poengsummer slik at begge er i samme metrikk eller har samme spredning. Nevnte transformasjon utføres ved å bruke følgende formel, hvor x er verdien a transform, µ er gjennomsnittet av den opprinnelige fordelingen og σ er standardavviket til opprinnelig distribusjon.
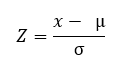
Resultatet som oppnås er skårer uttrykt i enheter for standardavvik og som oppfyller de nødvendige kravene til datasammenligning.
Scorer med samme senter. Uavhengig av gjennomsnittet av den opprinnelige fordelingen, når du transformerer til Z-score, blir gjennomsnittet av alle variabler null. I denne forstand tilsvarer positive Z-skårer skårer høyere enn det opprinnelige gjennomsnittet, mens negative skårer tilsvarer skårer lavere enn gjennomsnittet.
Scorer med samme spredning. Akkurat som gjennomsnittet av Z-skårene blir null, blir spredningen av alle variabler én.
Poeng med samme beregning. Beregningen for de nye poengsummene er uttrykt i enheter av standardavviket.
Selv om Z-poeng ikke har en minimums- eller maksimumsgrense, har de en tendens til å ta verdier mellom -3 og 3; de verdiene som overstiger disse verdiene representerer atypiske tilfeller, som vil trenge en annen type behandling.
Z-score er ikke de eneste metode transformasjon, et alternativt alternativ er persentilene, som refererer til den relative plasseringen av en poengsum som tar hensyn til prosentandelen av akkumulerte tilfeller. Denne transformasjonen utfører den samme prosessen som er beskrevet tidligere, og oppnår samme senter (50), samme dispersjon (0-100) og samme metrikk (prosentenheter).
Hovedforskjellen mellom begge transformasjonene ligger i endringen av formen på distribusjonen, siden i transformasjonen til persentiler endres dette, mens det i Z-skårene opprettholdes lik. Dette betyr at hvis datafordelingen er skjev, blir den symmetrisk når den transformeres til persentiler, men hvis den transformeres til Z-score vil den forbli asymmetrisk.