04/07/2021
0
Wyświetlenia


Analiza regresji jest prawdopodobnie najpowszechniej stosowaną techniką statystyczną wieloczynnikową w celu określenia zależności pomiędzy jedną lub grupę zmiennych niezależnych i zmiennej zależnej, tak aby ta pierwsza mogła przewidzieć zmianę drugi-
Niemal z natury ludzie próbują wyjaśniać zdarzenia, które dzieją się naturalnie. życie codzienne, „ta osoba pali, bo czuje się zestresowana”, „przejadanie się prowadzi do większej masy ciała”; Wiemy jednak, że wyjaśnienia, jakie dajemy takim wydarzeniom, nie zawsze są prawidłowe. Daniel Kahneman w swojej książce „Thinking Fast, Thinking Slow” opisuje, w jaki sposób, chociaż ludzie mają tendencję do wykorzystywania wszystkich elementów poznawczych, które posiadają, posiadają, zawsze będą popełniać błędy, próbując wyjaśnić jakieś wydarzenie, co jest całkowicie normalne w rzeczywistości, w której współistnieje wiele czynników. połowa. Jak więc moglibyśmy spróbować wyjaśnić wydarzenia tak dokładnie, jak to możliwe? W naukach społecznych i o zdrowiu można tego dokonać poprzez analizę danych; który definiuje się jako zestaw procedur wspomaganych technikami statystycznymi opisowe i wnioskowane w celu wydobycia informacji z empirycznej próbki danych i opracowania wnioski. W ramach analizy danych techniką, która pozwoli nam udzielić wiarygodnych wyjaśnień zdarzeń, jest technika wieloczynnikowa zwana analizą regresji.
Analiza regresji ma szereg wariantów, takich jak analiza regresji liniowej, analiza regresji wielokrotnej, Można rozważyć regresję logistyczną, analizę mediacji, analizę moderacji, a nawet modele równań strukturalnych (SEM). Jednak wszystkie te warianty opierają się na tej samej logice operacyjnej, jednej lub większej liczbie zmiennych wejściowych, które można nazwać predyktorami, zmiennymi niezależnymi, zmiennymi. zmienne objaśniające lub poprzedzające, przewidują największą możliwą wariancję zmiennej wyjściowej, którą można nazwać zmienną zależną lub po prostu kryterium; Jeśli istnieje więcej niż jedna zmienna niezależna, analiza regresji określa również, która z nich ma największy wpływ na zmienną zależną.
Aby zrozumieć, jak zachodzą te zależności, musimy odwołać się do następującego równania, które przedstawia prosty model regresji liniowej:
y = Balbo +BSiema X I
Gdzie,
Balbo = Początek nachylenia
BSiema = Stopień nachylenia linii (nachylenie)
X = wartość VI
e = reszty (błąd)
Mówiąc najprościej, równanie to wskazuje, w jakim stopniu obecność predyktora (zmiennej niezależnej) powoduje zmianę kryterium (zmiennej zależnej). Należy wspomnieć, że chociaż w równaniu jest mowa o reszcie (błądzie), nie jest ona szacowana w ramach modelu, elementu za co można krytykować tę technikę, ale że jej modele równań strukturalnych „ewolucji” (SEM) rekompensuje.
Po oszacowaniu równania można je zwizualizować za pomocą poniższej dwuwymiarowej płaszczyzny, zwanej linią regresji.
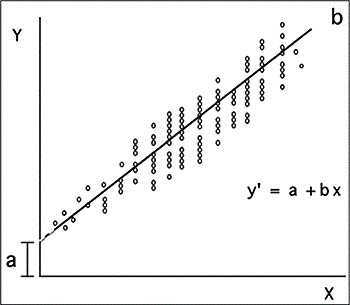
Źródło: Dagnino (2014)
Wykres ten, oprócz przedstawienia zależności między zaangażowanymi zmiennymi (poprzez chmurę punktów), eksponuje linię, która nadaje nazwę temu diagramowi i wskazuje, w jakim stopniu dane empiryczne odpowiadają wartości regresji (wartość B).
Chociaż B mówi nam stopień nachylenia, w rzeczywistości nie jest to zbyt przydatne do interpretacji, ponieważ Wyraża się ją w tej samej metryce co zmienne i dlatego jej wartości mogą być zbyt obszerne. W ten sposób, standaryzując B w oparciu o Z Score, uzyskuje się współczynnik beta (β), którego wartości mogą wynosić od 0 do 1, zarówno dodatnie, jak i ujemne, i które na to pozwala interpretacja. Zatem ujemna wartość beta będzie wskazywać, że zmienna predykcyjna negatywnie przewiduje kryterium, to znaczy im większa jest obecność predyktora, tym mniejsze prawdopodobieństwo obecności kryterium; Wręcz przeciwnie, dodatnia wartość beta wskazuje, że obecność predyktora sprzyja obecności kryterium.
Podobnie jak inne techniki statystyczne oparte na wnioskowaniu, interpretacja regresji będzie zależała od: kontrast hipotezy, czyli wartość istotności (p), która w naukach społecznych zazwyczaj wynosi p > .05.
Wreszcie elementarnym pojęciem analizy regresji jest wartość R2, która odnosi się do wariancji wyjaśnionej przez model. regresja, którą można zinterpretować bezpośrednio lub mnożąc ją przez 100, aby otrzymać procent wariancji wyjaśnione.
Jak wspomniano na początku, istnieją różne analizy regresji; regresja była już omawiana wcześniej proste liniowe i wielokrotne, zakładają, że zarówno zmienne predykcyjne, jak i kryterium są ciągłe. Jeżeli jednak zmienne nie są ciągłe, to znaczy są kategoryczne, należy zastosować analizę regresji logistycznej; Jest to jedyna różnica w stosunku do pozostałych modeli regresji.
Hayes, F. DO. (2018). Wprowadzenie do mediacji, moderacji i warunkowej analizy procesów. Podejście oparte na regresji. (2. Wydanie). Prasa Guilforda.