
04/07/2021


Z-poäng är resultatet av en transformation av data baserat på standardavvikelsen, med syftet att göra jämförelser mellan variabler.
För att fördjupa konceptet och delarna av Z-poäng är det nödvändigt att granska några relaterade tidigare koncept som kommer att underlätta deras förståelse.
Centrum. Det hänvisar till värdet på den eller de variabler som med största sannolikhet finns i vår data. Det vanligaste värdet för centret är medelvärdet eller medelvärdet, vilket erhålls genom att lägga till alla data och dividera dem med mängden data de har.
Dispersion. Det hänvisar till graden av avstånd eller koncentration av värdena med avseende på mitten av variablerna. De vanligaste spridningsdata är 1) Standardavvikelse eller standardavvikelse, som talar om för oss hur långt data är från medelvärdet. Detta beräknas genom att subtrahera medelvärdet från varje data och höja det till kvadraten, sedan beräknas medelvärdet av dessa värden och slutligen utvärderas kvadratroten av detta nya medelvärde; 2)
Variation, detta visar sig vara standardavvikelsen men upphöjd till kvadraten, den erhålls enligt samma procedur för standardavvikelsen, men utan att kvadratroten beräknas.Formen på distribution. Återspeglar hur ofta ett värde eller värdeintervall upprepas. Det är nödvändigt att skilja mellan teoretiska fördelningar, som formulerar matematik, medan empiriska fördelningar bildas av de värden som en variabel tar i ett urval.
förresten syntes, vi skulle kunna säga att centret är en representant för data, spridningen hjälper till att specificera om centret är en bra eller dålig representation av data och formen på fördelningen hjälper till att upptäcka var data är grupperade värden.
En av de vanligaste uppgifterna som utförs i undersökning är jämförelse av två eller flera olika variabler, men vid många tillfällen står forskarna inför problemet att deras data inte kan jämföras eftersom variabler presenterar ett centrum eller en helt annan fördelning eller ännu värre, de har olika mått, det vill säga de mättes på ett annat sätt (till exempel skalorna Wechsler, för att mäta intelligenskvotienten, har en serie tester som kvalificerar sig från exekveringstiden, de korrekta svaren eller frånvaron eller närvaron av svar). för sådan anledning Det återstår att undra hur man löser detta problem?
Svaret är tydligt, en transformation av datan måste utföras i Z-poäng eller typiska poäng så att båda är i samma mått eller har samma spridning. Nämnda transformation utförs med hjälp av följande formel, där x är värdet a transform, µ är medelvärdet av den ursprungliga fördelningen och σ är standardavvikelsen för ursprunglig distribution.
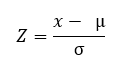
Resultatet som erhålls är poäng uttryckta i enheter av standardavvikelse och som uppfyller de nödvändiga kraven för datajämförelse.
Gör mål med samma center. Oavsett medelvärdet av den ursprungliga fördelningen, när du transformerar till Z-poäng blir medelvärdet av alla variabler noll. I denna mening motsvarar positiva Z-poäng poäng högre än det ursprungliga medelvärdet, medan negativa poäng motsvarar poäng lägre än medelvärdet.
Poäng med samma spridning. Precis som medelvärdet av Z-poängen blir noll, blir spridningen av alla variabler en.
Poäng med samma mätvärde. Måttet för de nya poängen uttrycks i enheter av standardavvikelsen.
Även om Z-poäng inte har en minimi- eller maximigräns, tenderar de att ta värden mellan -3 och 3; de värden som överstiger dessa värden representerar atypiska fall, som skulle behöva en annan typ av behandling.
Z-poäng är inte de enda metod transformation, ett alternativt alternativ är percentilerna, som hänvisar till den relativa positionen för en poäng med hänsyn till procentandelen ackumulerade fall. Denna transformation utför samma process som tidigare beskrivits, och erhåller samma centrum (50), samma spridning (0-100) och samma metrik (procentenheter).
Huvudskillnaden mellan båda transformationerna ligger i förändringen av fördelningens form, eftersom detta ändras i omvandlingen till percentiler, medan det i Z-poängen bibehålls likvärdig. Detta innebär att om datafördelningen är skev, när den omvandlas till percentiler blir den symmetrisk, men om den omvandlas till Z-poäng kommer den att förbli asymmetrisk.
