0
Visningar


Regressionsanalys är möjligen den mest använda multivariata statistiska tekniken för att bestämma sambandet mellan en, eller en grupp, av oberoende variabler och en beroende så att den förra kan förutsäga förändringen i andra-
Nästan medfödd försöker människor att ge förklaringar till de händelser som sker naturligt. vardagen, "den personen röker för att han känner sig stressad", "att äta för mycket leder till större kroppsvikt"; Vi vet dock att de förklaringar vi ger till sådana händelser inte alltid är korrekta. Daniel Kahneman beskriver i sin bok "Thinking Fast, Thinking Slow" hur, även om människor tenderar att använda alla kognitiva element de besitter kommer de alltid att göra misstag när de försöker förklara någon händelse, vilket är helt normalt i en verklighet där flera faktorer samexisterar. halv. Så hur kan vi försöka förklara händelser så exakt som möjligt? Inom samhälls- och hälsovetenskapen är det möjligt att göra detta genom dataanalys; som definieras som en uppsättning procedurer som stöds av statistiska tekniker beskrivande och inferentiella för att extrahera information från ett empiriskt urval av data och utveckla Slutsatser. Inom dataanalys är tekniken som gör att vi kan ge tillförlitliga förklaringar till händelser en multivariat teknik som kallas regressionsanalys.
Regressionsanalys har en serie varianter som linjär regressionsanalys, multipel regressionsanalys, logistisk regression, medlingsanalys, modereringsanalys och till och med strukturella ekvationsmodeller kan övervägas (SEM). Alla dessa varianter följer dock samma operationella logik, en eller flera indatavariabler, som kan kallas prediktorer, oberoende variabler, variabler. förklarande eller föregående variabler, förutsäga den största möjliga variansen för en utdatavariabel, som kan kallas den beroende variabeln eller helt enkelt kriterium; När det finns mer än en oberoende variabel avgör regressionsanalysen också vilken av dessa som har störst inflytande på den beroende variabeln.
För att förstå hur dessa samband uppstår måste vi tillgripa följande ekvation, som presenterar en enkel linjär regressionsmodell:
y = Bantingen +BYo x och
Var,
bantingen = Slutningens ursprung
bYo = Linjens lutning (lutning)
X = VI-värde
e = rester (fel)
Enkelt uttryckt indikerar denna ekvation i vilken grad närvaron av en prediktor (oberoende variabel) ger en förändring i kriteriet (beroende variabel). Det är nödvändigt att nämna att även om ekvationen nämner resterande (fel) så uppskattas den inte inom modellen, elementet för vilken denna teknik kan kritiseras, men att dess "evolution" strukturella ekvationsmodeller (SEM) kompenserar.
När ekvationen väl har uppskattats kan den visualiseras med hjälp av följande tvådimensionella plan, kallad regressionslinjen.
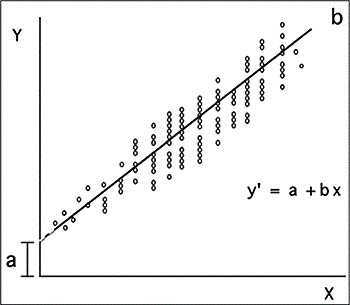
Källa: Dagnino (2014)
Den här grafen, förutom att presentera förhållandet mellan de inblandade variablerna (genom molnet av punkter), exponerar en linje som ger detta diagram namn och anger i vilken grad de empiriska data passar regressionsvärdet (värdet av B).
Även om B berättar graden av lutningen, är det faktiskt inte särskilt användbart för tolkning eftersom Det uttrycks i samma mått som variablerna och därför kan dess värden vara för omfattande. På detta sätt, genom att standardisera B baserat på Z-poängen, erhålls betakoefficienten (β), vars värden kan vara mellan 0 och 1, både positiva och negativa och som tillåter dess tolkning. Således kommer ett negativt betavärde att indikera att prediktorvariabeln negativt förutsäger kriteriet, det vill säga ju större närvaron av prediktorn är, desto mindre sannolikt är närvaron av kriteriet; Tvärtom indikerar en positiv beta att förekomsten av prediktorn gynnar närvaron av kriteriet.
Liksom andra inferentiella statistiska tekniker kommer tolkningen av en regression att bero på hypoteskontrast, eller signifikansvärdet (p), som inom samhällsvetenskap typiskt är p > .05.
Slutligen är ett elementärt begrepp för regressionsanalys R2-värdet, vilket hänvisar till variansen som förklaras av modellen. regression, som kan tolkas direkt eller genom att multiplicera den med 100 för att få procentuell varians förklarade.
Som nämnts inledningsvis finns det olika regressionsanalyser, regression behandlades tidigare enkel linjär och multipel, dessa antar att både prediktorvariablerna och kriteriet är kontinuerliga. Men när variablerna inte är kontinuerliga, det vill säga de är kategoriska, måste logistisk regressionsanalys användas; Detta är den enda skillnaden med resten av regressionsmodellerna.
Hayes, F. TILL. (2018). Introduktion till medling, moderering och villkorad processanalys. Ett regressionsbaserat tillvägagångssätt. (2:a. Utgåva). Guilford Press.

