13/11/2021
0
Visninger


Z-score er resultatet af en transformation af data baseret på standardafvigelsen med det formål at foretage sammenligninger mellem variabler.
For at uddybe konceptet og elementerne i Z-score er det nødvendigt at gennemgå nogle relaterede tidligere koncepter, der vil lette deres forståelse.
Centrum. Det refererer til værdien af den eller de variabler, der med størst sandsynlighed findes i vores data. Den mest almindelige værdi af centret er middelværdien eller gennemsnittet, som fås ved at tilføje alle data og dividere dem med mængden af data, de har.
Spredning. Det refererer til graden af afstand eller koncentration af værdierne i forhold til midten af variablerne. De mest almindelige spredningsdata er 1) Standardafvigelse eller standardafvigelse, som fortæller os, hvor langt dataene er fra middelværdien. Dette beregnes ved at trække middelværdien fra hver data og hæve den til kvadratet, derefter beregnes middelværdien af disse værdier og til sidst evalueres kvadratroden af denne nye middelværdi; 2)
Varians, dette viser sig at være standardafvigelsen, men hævet til kvadratet, opnås den efter samme procedure for standardafvigelsen, men uden beregning af kvadratroden.Formen af fordeling. Afspejler, hvor ofte en værdi eller et område af værdier gentages. Det er nødvendigt at skelne mellem teoretiske fordelinger, som formulerer matematik, mens empiriske fordelinger dannes af de værdier, som en variabel tager i en stikprøve.
ved hjælp af syntese, vi kunne sige, at centret er en repræsentant for dataene, hjælper spredningen med at specificere, om centret er en god eller dårlig repræsentation af dataene og formen på fordelingen hjælper med at opdage, hvor dataene er grupperet værdier.
En af de mest almindelige opgaver, der udføres i efterforskning er sammenligning af to eller flere forskellige variabler, står forskerne imidlertid ved mange lejligheder over for det problem, at deres data ikke kan sammenlignes, fordi variabler præsenterer et centrum eller en meget anderledes fordeling eller endnu værre, de har forskellige metrikker, dvs. de blev målt på en anden måde (f.eks. skalaerne Wechsler, for at måle intelligenskvotienten, har en række tests, der kvalificerer sig fra udførelsestidspunktet, de korrekte svar eller fraværet eller tilstedeværelsen af svar). for sådan grund Det er stadig at spørge, hvordan man løser dette problem?
Svaret er klart, en transformation af data skal udføres i Z-score eller typiske scoringer så begge er i samme metrik eller har samme spredning. Nævnte transformation udføres ved hjælp af følgende formel, hvor x er værdien a transformere, µ er middelværdien af den oprindelige fordeling og σ er standardafvigelsen af original distribution.
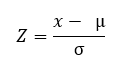
Det opnåede resultat er scores udtrykt i standardafvigelsesenheder, og som opfylder de nødvendige krav til datasammenligning.
Scorer med samme center. Uanset gennemsnittet af den oprindelige fordeling, når du transformerer til Z-score, bliver middelværdien af alle variable nul. I denne forstand svarer positive Z-scores til scores højere end det oprindelige gennemsnit, mens negative scores svarer til scores, der er lavere end gennemsnittet.
Scorer med samme spredning. Ligesom middelværdien af Z-scorerne bliver nul, bliver spredningen af alle variabler én.
Scorer med samme metrik. Metrikken for de nye scores er udtrykt i enheder af standardafvigelsen.
Selvom Z-score ikke har en minimums- eller maksimumgrænse, har de en tendens til at tage værdier mellem -3 og 3; de værdier, der overstiger disse værdier, repræsenterer atypiske tilfælde, som ville kræve en anden type behandling.
Z-score er ikke de eneste metode transformation, er en alternativ mulighed percentilerne, som refererer til den relative placering af en score under hensyntagen til procentdelen af akkumulerede tilfælde. Denne transformation udfører den samme proces, der tidligere er beskrevet, og opnår det samme center (50), den samme dispersion (0-100) og den samme metrik (procentenheder).
Hovedforskellen mellem begge transformationer ligger i ændringen af fordelingens form, da dette i transformationen til percentiler ændres, mens det i Z-scorerne bibeholdes lige. Dette betyder, at hvis datafordelingen er skæv, bliver den symmetrisk, når den transformeres til percentiler, men hvis den transformeres til Z-score, vil den forblive asymmetrisk.

