0
Vues


L'analyse de régression est probablement la technique statistique multivariée la plus largement utilisée pour déterminer la relation entre une, ou un groupe, de variables indépendantes et une variable dépendante afin que la première puisse prédire le changement de la deuxième-
De manière presque innée, l’être humain essaie de donner des explications aux événements qui se produisent naturellement. dans la vie de tous les jours, « cette personne fume parce qu'elle se sent stressée », « trop manger entraîne une prise de poids »; Cependant, nous savons que les explications que nous donnons à de tels événements ne sont pas toujours exactes. Daniel Kahneman dans son livre « Thinking Fast, Thinking Slow » décrit comment, même si les gens ont tendance à utiliser tous les éléments cognitifs dont ils possèdent, ils feront toujours des erreurs en essayant d’expliquer un événement, ce qui est tout à fait normal dans une réalité où plusieurs facteurs coexistent. moitié. Alors, comment pourrions-nous essayer d’expliquer les événements aussi précisément que possible? Dans les sciences sociales et de la santé, il est possible d’y parvenir grâce à l’analyse des données; qui se définit comme un ensemble de procédures aidées par des techniques statistiques descriptif et inférentiel afin d'extraire des informations à partir d'un échantillon empirique de données et de développer conclusions. Dans le cadre de l'analyse des données, la technique qui nous permettra de donner des explications fiables aux événements est une technique multivariée appelée analyse de régression.
L'analyse de régression comporte une série de variantes telles que l'analyse de régression linéaire, l'analyse de régression multiple, la régression logistique, l'analyse de médiation, l'analyse de modération et même des modèles d'équations structurelles pourraient être envisagés (SEM). Cependant, toutes ces variantes suivent la même logique opérationnelle, une ou plusieurs variables d'entrée, que l'on peut appeler prédicteurs, variables indépendantes, variables. les variables explicatives ou antécédentes, prédisent la plus grande quantité possible de variance d'une variable de sortie, qui peut être connue sous le nom de variable dépendante ou simplement critère; Lorsqu'il y a plus d'une variable indépendante, l'analyse de régression détermine également laquelle d'entre elles a la plus grande influence sur la variable dépendante.
Pour comprendre comment ces relations se produisent, nous devons recourir à l’équation suivante, qui présente un modèle de régression linéaire simple :
y = Bsoit +BYo X et
Où,
bsoit = Origine de la pente
bYo = Degré d'inclinaison de la ligne (pente)
X = valeur VI
e = Résidus (erreur)
En termes simples, cette équation indique dans quelle mesure la présence d'un prédicteur (variable indépendante) produit un changement dans le critère (variable dépendante). Il faut mentionner que bien que l'équation mentionne le résidu (erreur) celui-ci n'est pas estimé dans le modèle, élément pour lequel cette technique peut être critiquée, mais que ses modèles d’équations structurelles « évolutives » (SEM) compense.
Une fois l’équation estimée, elle peut être visualisée à l’aide du plan bidimensionnel suivant, appelé droite de régression.
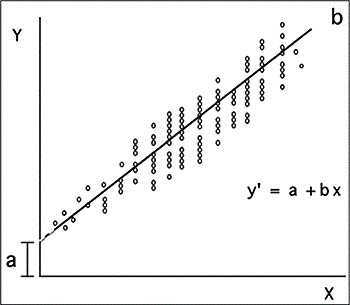
Source: Dagnino (2014)
Ce graphique, en plus de présenter la relation entre les variables impliquées (à travers le nuage de points), expose une ligne qui donne le nom à ce diagramme et indique dans quelle mesure les données empiriques correspondent à la valeur de régression (la valeur de B).
Bien que B nous indique le degré de la pente, il n’est en réalité pas très utile pour l’interprétation car Il est exprimé dans la même métrique que les variables et, par conséquent, ses valeurs peuvent être trop étendues. De cette façon, en standardisant B sur la base des Z Scores, le coefficient bêta est obtenu (β), dont les valeurs peuvent être comprises entre 0 et 1, aussi bien positives que négatives et qui permet sa interprétation. Ainsi, une valeur bêta négative indiquera que la variable prédictive prédit négativement le critère, c'est-à-dire que plus la présence du prédicteur est grande, moins la présence du critère est probable; Au contraire, un bêta positif indique que la présence du prédicteur favorise la présence du critère.
Comme d’autres techniques statistiques inférentielles, l’interprétation d’une régression dépendra de la contraste d'hypothèse, ou la valeur de signification (p), qui en sciences sociales est généralement p > .05.
Enfin, un concept élémentaire de l'analyse de régression est la valeur R2, qui fait référence à la variance expliquée par le modèle. régression, qui peut être interprétée directement ou en la multipliant par 100 pour obtenir le pourcentage de variance expliqué.
Comme mentionné au début, il existe différentes analyses de régression; la régression a déjà été abordée simples, linéaires et multiples, celles-ci supposent que les variables prédictives et le critère sont continus. Cependant, lorsque les variables ne sont pas continues, c'est-à-dire qu'elles sont catégorielles, une analyse de régression logistique doit être utilisée; C’est la seule différence avec les autres modèles de régression.
Hayes, F. À. (2018). Introduction à la médiation, à la modération et à l'analyse des processus conditionnels. Une approche basée sur la régression. (2ème. Édition). Presse Guilford.