31/01/2022
0
विचारों


चर के बीच तुलना करने के उद्देश्य से मानक विचलन के आधार पर डेटा के परिवर्तन से जेड स्कोर का परिणाम होता है।
Z स्कोर की अवधारणा और तत्वों को गहरा करने के लिए, कुछ संबंधित पिछली अवधारणाओं की समीक्षा करना आवश्यक है जो उनकी सुविधा प्रदान करेंगे समझ.
केंद्र. यह वेरिएबल या वेरिएबल्स के मान को संदर्भित करता है जो हमारे डेटा में पाए जाने की सबसे अधिक संभावना है। केंद्र का सबसे सामान्य मूल्य माध्य या औसत है, जो सभी डेटा को जोड़कर और उन्हें उनके पास मौजूद डेटा की मात्रा से विभाजित करके प्राप्त किया जाता है।
फैलाव. यह चर के केंद्र के संबंध में मूल्यों की दूरी या एकाग्रता की डिग्री को संदर्भित करता है। सबसे आम फैलाव डेटा हैं 1) मानक विचलन या मानक विचलन, जो हमें बताता है कि डेटा माध्य से कितनी दूर है। इसकी गणना प्रत्येक डेटा से औसत मान घटाकर और इसे वर्ग तक बढ़ाकर की जाती है, फिर इन मूल्यों के माध्य की गणना की जाती है और अंत में इस नए माध्य के वर्गमूल का मूल्यांकन किया जाता है; 2) झगड़ा, यह मानक विचलन हो जाता है लेकिन वर्ग तक बढ़ा दिया जाता है, यह मानक विचलन के लिए समान प्रक्रिया का पालन करते हुए प्राप्त किया जाता है, लेकिन वर्गमूल की गणना किए बिना।
का आकार वितरण. दर्शाता है कि कितनी बार कोई मान या मानों की श्रेणी दोहराई जाती है। सैद्धांतिक वितरण के बीच अंतर करना आवश्यक है, जो तैयार करता है गणित, जबकि अनुभवजन्य वितरण उन मानों से बनते हैं जो एक चर एक नमूने में लेता है।
के माध्यम से संश्लेषण, हम कह सकते हैं कि केंद्र डेटा का प्रतिनिधि है, फैलाव यह निर्दिष्ट करने में मदद करता है कि केंद्र है या नहीं डेटा का अच्छा या बुरा प्रतिनिधित्व और वितरण का आकार यह पता लगाने में मदद करता है कि डेटा को कहाँ समूहीकृत किया गया है मान।
में किए जाने वाले सबसे सामान्य कार्यों में से एक है जाँच पड़ताल है तुलना हालांकि, दो या दो से अधिक विभिन्न चरों के कारण, कई मौकों पर शोधकर्ताओं को इस समस्या का सामना करना पड़ता है कि उनके डेटा की तुलना नहीं की जा सकती क्योंकि चर एक केंद्र या एक बहुत अलग वितरण या इससे भी बदतर प्रस्तुत करते हैं, उनके पास अलग-अलग मेट्रिक्स हैं, अर्थात, उन्हें एक अलग तरीके से मापा गया था (उदाहरण के लिए, तराजू वेचस्लर, बुद्धि भागफल को मापने के लिए, परीक्षणों की एक श्रृंखला है जो निष्पादन समय, सही उत्तर या अनुपस्थिति या उपस्थिति से योग्यता प्राप्त करते हैं उत्तर)। इस तरह के लिए कारण यह आश्चर्य की बात बनी हुई है कि इस समस्या को कैसे हल किया जाए?
उत्तर स्पष्ट है, डेटा का रूपांतरण में किया जाना चाहिए Z स्कोर या विशिष्ट स्कोर ताकि दोनों एक ही मीट्रिक में हों या एक ही फैलाव हो। उक्त परिवर्तन निम्न सूत्र का उपयोग करके किया जाता है, जहाँ x मान a है परिवर्तन, μ मूल वितरण का मतलब है और σ का मानक विचलन है मूल वितरण।
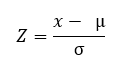
प्राप्त परिणाम मानक विचलन की इकाइयों में व्यक्त किए गए स्कोर हैं और जो डेटा तुलना के लिए आवश्यक आवश्यकताओं को पूरा करते हैं।
एक ही केंद्र के साथ स्कोर. मूल वितरण के माध्य के बावजूद, जब आप Z स्कोर में बदलते हैं तो सभी चरों का माध्य शून्य हो जाता है। इस अर्थ में, सकारात्मक Z स्कोर मूल माध्य से अधिक स्कोर के अनुरूप होते हैं, जबकि नकारात्मक स्कोर माध्य से कम स्कोर के अनुरूप होते हैं।
समान स्प्रेड के साथ स्कोर. जिस तरह Z स्कोर का माध्य शून्य हो जाता है, वैसे ही सभी चरों का प्रसार एक हो जाता है।
एक ही मीट्रिक के साथ स्कोर. नए अंकों के लिए मीट्रिक मानक विचलन की इकाइयों में व्यक्त की जाती है।
हालाँकि Z स्कोर की न्यूनतम या अधिकतम सीमा नहीं है, वे -3 और 3 के बीच मान लेते हैं; वे मान जो इन मूल्यों से अधिक हैं, असामान्य मामलों का प्रतिनिधित्व करते हैं, जिन्हें दूसरे प्रकार के उपचार की आवश्यकता होगी।
Z स्कोर ही नहीं हैं तरीका परिवर्तन, एक वैकल्पिक विकल्प प्रतिशतक है, जो संचित मामलों के प्रतिशत को ध्यान में रखते हुए स्कोर की सापेक्ष स्थिति को संदर्भित करता है। यह परिवर्तन वही प्रक्रिया करता है जो पहले बताई गई थी, समान केंद्र (50), समान फैलाव (0-100) और समान मीट्रिक (प्रतिशत इकाइयाँ) प्राप्त करना।
दोनों परिवर्तनों के बीच मुख्य अंतर वितरण के आकार के परिवर्तन में रहता है, चूँकि पर्सेंटाइल में रूपांतरण में इसे बदल दिया जाता है, जबकि Z स्कोर में इसे बनाए रखा जाता है बराबर। इसका मतलब यह है कि, यदि डेटा वितरण तिरछा है, तो प्रतिशतक में परिवर्तित होने पर यह सममित हो जाता है, लेकिन यदि इसे Z स्कोर में परिवर्तित किया जाता है तो यह असममित रहेगा।
